一只鸟类掠过监测区域,红外镜头可完成上千次连续帧抓取。这并非夸张表述:在某国家级自然保护区,研究团队部署200台红外监测相机,经过180天连续不间断监测,累计采集原始影像超30万张——而其中80%以上为植被摆动、环境温差等干扰因素触发的无效影像(以下简称“废片”),无法为生物多样性研究提供有效数据支撑。
面对海量监测数据带来的“数据治理困境”,生态科研工作者常面临以下核心痛点,严重制约研究效率与AI模型研发进程:
——“监测数据总量持续增长,但数据处理效率与价值挖掘能力严重脱节,数据规范化管理已成为生物多样性精准研究的核心瓶颈。”
一、数据爆炸时代,生物多样性监测的核心困局
当前,生物多样性保护已进入精准化、数字化治理阶段,红外相机、声纹记录仪、高清视频监控等监测设备广泛应用于野外生态监测场景,这类设备每年产生的监测数据以TB级规模持续增长,为物种多样性调查、种群动态分析提供了海量数据基础。
但需明确的是:数据量的增长并不等同于认知能力的提升,三大核心痛点导致海量监测数据反而成为科研负担,难以转化为有效科研资源:
① 无效数据占比极高:受野外环境干扰(如植被随风摆动、昼夜温差变化、光照波动等),红外相机易发生误触发,导致废片率高达80%以上,有效动物影像被海量无效数据淹没,大幅增加数据处理的时间成本与人力成本。
② 数据碎片化问题突出:各监测位点的监测数据分散存储于不同设备或终端,缺乏统一的规范化管理标准与集中式存储体系,导致跨区域、跨周期的物种对比研究、种群动态分析难以开展,数据复用率极低。
③ 标注效率低下,模型迭代滞后:基层科研人员需依靠人工逐帧鉴定、手动标注有效影像,不仅标注精度受主观因素影响,且标注效率极低,直接导致AI监测模型的更新周期长,严重制约AI技术在生物多样性监测中的应用效能。
二、南创科技自主研发:AI+预处理+标注一体化智能平台
针对上述生物多样性监测中的数据治理与模型迭代痛点,安徽南创生态科技有限公司自主研发推出“AI+图像预处理+标注一体化平台”,核心设计理念为:“实现监测数据的规范化治理与价值转化,加速AI监测模型迭代,为生物多样性精准保护提供技术支撑”。
该平台采用“桌面端预处理+网页端协同标注”的双端协同架构,打通从野外数据采集、无效数据筛选、数据规范化归档,到多人协同标注、训练集构建、模型迭代的全链路,实现监测数据从“原始数据”到“科研资产”的高效转化。
(一)核心能力一:边缘计算赋能,就地完成无效数据筛选
桌面端预处理软件可部署于本地高性能计算机(推荐配置高性能GPU,提升数据处理速率),内置通用基础模型(Foundation Models),可对红外影像、野外视频、声纹数据进行实时AI预标记与无效数据筛选,核心实现三大功能:
1、影像有效性判断:自动识别图像中是否存在活动生物体,精准区分生物体与背景干扰物,排除无生物体的空拍影像;
2、声纹有效性过滤:自动识别声纹片段中是否包含有效动物鸣叫,剔除风声、雨声、人为干扰等无效声纹数据;
3、无效数据直接剔除:对无意义空拍、纯背景干扰等无效内容进行批量剔除,从源头减少数据处理工作量。
此外,本地预处理模块支持按数据采集地点、拍摄时间、设备编号等核心维度,对筛选后的有效数据进行批量重命名与结构化归档,构建标准化、可检索的数据资产库,为后续大规模AI模型训练奠定坚实基础。
“数据在上传至云端标注系统之前,已完成第一轮智能筛选与规范化处理,这一步可减少科研人员80%的无效劳动,将更多精力投入到数据价值挖掘与科研分析中。”
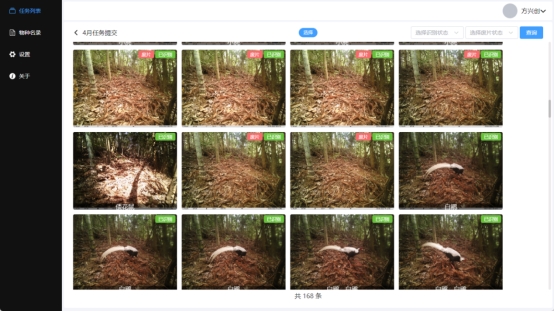
(二)核心能力二:AI辅助标注,聚焦专家核心科研价值
网页端作为整个平台的核心管控与协同中枢,承担多人协同标注、标注任务分发、标注质量管控及模型训练辅助等功能,核心目标是“解放科研人员的重复性标注劳动,让专家聚焦于物种鉴定、特征分析等核心科研工作”。
1. 多维度图像标注体系,兼顾精度与效率
平台突破传统单一标注模式,集成深度学习模型辅助标注(Model-Assisted Labeling)技术,实现标注效率与精度的双重提升,具体功能包括:
自动生成初始边界框(Bounding Box):对图像中的活体目标进行精准识别,自动拉取边界框,减少人工手动画框的工作量;
物种初步智能推荐:基于内置物种数据库,对标注目标给出初步物种归属建议,辅助科研人员快速完成物种鉴定与标注。
为满足科研需求,平台构建多维度标注体系,具体标注维度及可标注内容如下表所示:

2. 精细化声纹标注,挖掘声学监测数据价值
传统音频标注仅能实现“物种识别”的基础功能,南创科技平台突破这一局限,构建细粒度、多维度的声纹标注体系,实现声学监测数据的深度价值挖掘,具体包括四大标注模块:
📌 事件标注:对音频流中的特定动物鸣叫事件进行精准时段截取(明确起始时间与结束时间),赋予对应物种标签,构建可检索、可复用的声学事件数据库,为物种活动节律分析提供支撑。
📌 物种标注:精准识别发声个体的物种归属,支持多物种共存录音中的分离标注,有效剔除干扰声纹,为AI模型训练提供纯净的单物种训练样本,提升模型识别精度。
📌 声学质量与环境噪声标注:对背景噪声类型(如雨声、风声、人为活动干扰噪声、设备本身噪声等)进行精准标记,并对音频信噪比进行分级标注,助力AI模型学习“噪声环境下的物种声纹识别”能力,提升模型识别鲁棒性。
📌 时序与声学参数辅助标注:自动提取音频的基频(F0)、时程、频率调制、频谱特征等核心声学参数,并提供辅助标注功能,为声学特征工程、物种声学差异分析提供精准的参数依据。
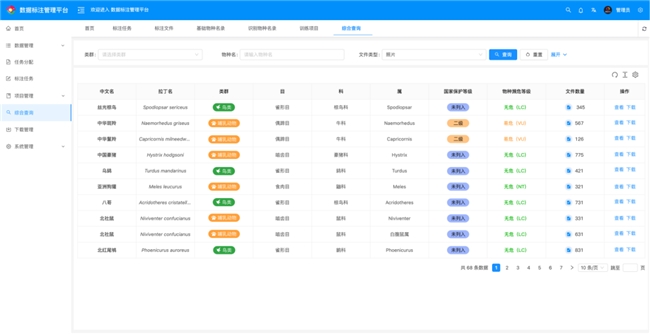
(三)核心能力三:数据资产化管理,实现标注成果高效复用
传统监测模式下,设备采集的海量数据多为“分散存储、难以复用”的负担,南创科技一体化平台通过规范化治理与资产化管理,将监测数据转化为可量化、可分析、可复用的数字科研资产。
平台内置“综合查询”功能,用户可通过多维度组合查询,实现有效数据的秒级检索,查询维度包括:物种类群、物种名称、拍摄时间(白昼/夜晚)、地理位置、生境类型等。查询结果不仅包含对应数据文件,还将自动生成完整的数据资产报告,核心内容包括:
物种分布资产:特定区域内目标物种的地理坐标分布、活动频率、活动时段等核心信息,为种群动态分析提供数据支撑;
标注资产统计:已标注图片数量、已标注声纹片段时长、标注完成率、数据质量评级、模型训练就绪状态等,实现标注成果的可视化管理。
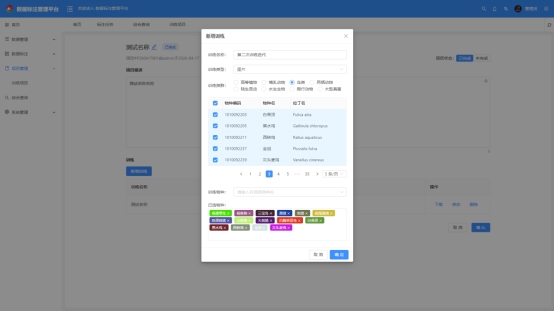
(四)核心能力四:一键构建标准化训练集,推动模型迭代效率提升10倍
这套一体化平台的核心价值,最终指向“加速AI监测模型迭代”,助力科研团队快速构建高性能生态监测AI模型。用户可根据具体研究需求与物种名录,从数据资产库中快速抽取符合条件的已标注数据,系统将自动完成三大核心操作,无需人工干预:
1、数据集智能划分:自动按科学比例划分训练集、验证集、测试集,确保数据集的代表性与合理性,为模型训练与性能验证提供保障;
2、数据增强策略配置:根据数据类型(影像/声纹)自动匹配最优数据增强策略,提升模型泛化能力;
3、训练任务一键提交:完成数据集配置后,可直接提交模型训练任务,实现“数据标注-训练集构建-模型训练”的无缝衔接,大幅缩短模型迭代周期。
结语:不止是工具,更是生物多样性研究的AI能力加速器
南创科技构建这套“AI+图像预处理+标注一体化平台”的核心逻辑,并非单纯提升数据标注效率,而是搭建一套闭环的AI模型研发飞轮,实现监测数据的全链路价值转化:
野外数据采集 → 本地AI预处理(无效数据筛选+规范化归档) → 云端多人协同标注 → 数据资产沉淀 → 自动构建标准化训练集 → 模型训练与迭代优化
当每一张野外影像都能被高效筛选、每一段动物鸣叫都能被精准标注、每一份监测数据都能沉淀为可复用的科研资产,AI监测模型的进化将不再是偶发的技术突破,而是可复制、可推广的系统性积累。
安徽南创生态科技有限公司自主研发的“AI+预处理+标注一体化平台”正逐步将生态监测领域的“数据黑洞”转化为“智慧引擎”,通过数字化、智能化技术,为全球生物多样性精准保护、生态环境治理,构建更科学、更精准的数字蓝图。
审核:王峰 郭江涛 石贵明
校对:小强




